Your First Model: y = mx + b
- How a simple linear equation is a machine learning model
- What "training" actually does — finds
mandb - Your first taste of scikit-learn code
The simplest model in the world
You already know the equation of a line:
\\[ y = mx + b \\]
This is a model. Give it an x, it gives you back a y. The numbers m (slope) and b (intercept) are the model — they're what gets "learned" during training.
Concrete example: Celsius to Fahrenheit
Pretend you don't know the conversion formula. You only have a bunch of paired observations from a thermometer that shows both scales:
| Celsius (x) | Fahrenheit (y) |
|---|---|
| 0 | 32 |
| 10 | 50 |
| 20 | 68 |
| 37 | 98.6 |
| 100 | 212 |
Plot it:
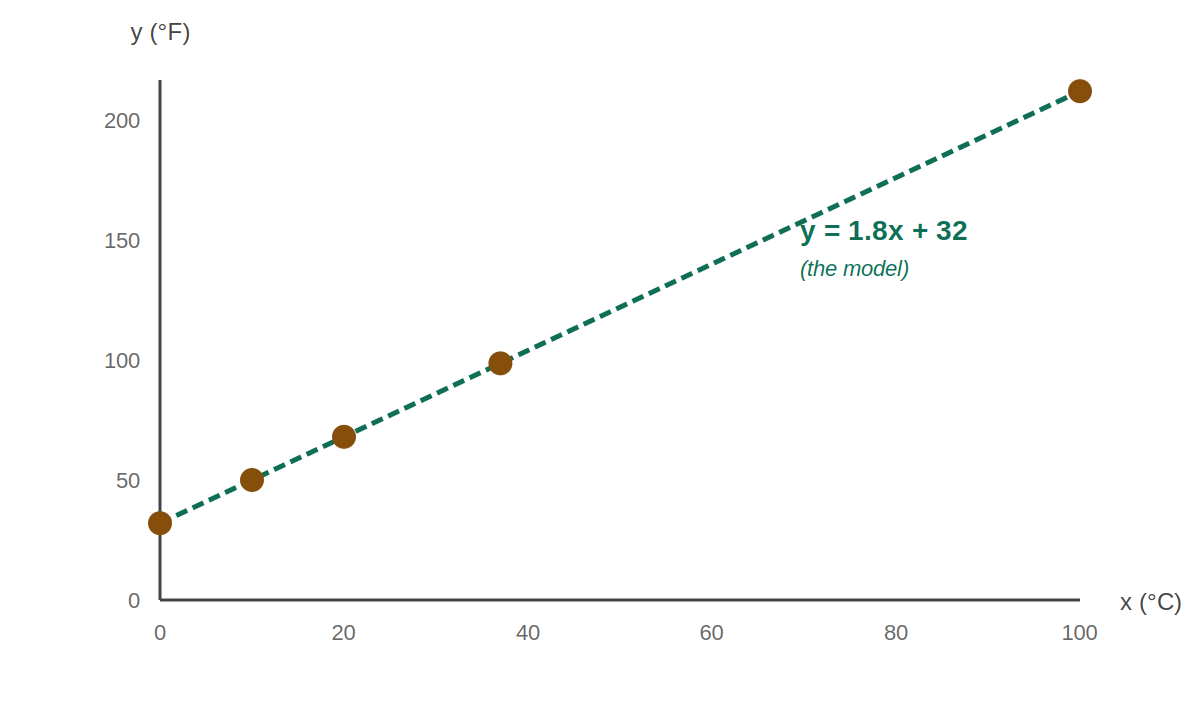
A line fits these points perfectly. The slope m ≈ 1.8 and intercept b ≈ 32. The model is y = 1.8x + 32.
Training is just the process of finding the best
m and b from data. The model isn't the equation — the equation is the same for every line. The model is the specific numbers m=1.8 and b=32 that came out of training.
Doing it in scikit-learn (your first ML code)
import numpy as np
from sklearn.linear_model import LinearRegression
# The data — Celsius and Fahrenheit
X = np.array([[0], [10], [20], [37], [100]]) # inputs (note the brackets!)
y = np.array([32, 50, 68, 98.6, 212]) # outputs
# Create the model
model = LinearRegression()
# Train it (this is where m and b are found)
model.fit(X, y)
# Inspect what was learned
print(f"m (slope) = {model.coef_[0]:.4f}")
print(f"b (intercept) = {model.intercept_:.4f}")
# Use it to predict
print(f"25°C is predicted to be {model.predict([[25]])[0]:.1f}°F")
Running this prints:
m (slope) = 1.8000
b (intercept) = 32.0000
25°C is predicted to be 77.0°FThat's it. You just trained a machine learning model. The whole course is going to feel like this same pattern — load data, create a model, call .fit(), call .predict() — over and over with different algorithms.
Try it interactively
Open TensorFlow Playground and watch a neural network "find the rule" for a problem you can't draw a single line through. Set the dataset to the spiral (bottom right) and click play. Notice how the network's "rule" gets more complex as training progresses — it's doing the same fundamental thing as our Celsius example, just with thousands of parameters instead of two.
A subtle but important point
XNotice we wrote
X = np.array([[0], [10], [20], ...]) — each value is in its own list. scikit-learn always expects inputs as a 2D array (rows = examples, columns = features), even when there's only one feature. Forgetting this is the most common beginner error and produces a confusing error message. We'll see why this matters in Module 4.
Check your understanding
- In
y = mx + b, after training, what part is "the model"? - If you had only one data point (say, 20°C = 68°F), could you train this model? Why or why not?
- What does
model.fit(X, y)actually do, in plain English?
Show answers
- The specific values of
mandbthat came out of training. The equation form is the same for every line — only the numbers are learned. - No — with one point, infinitely many lines pass through it. You need at least 2 points to define a line (and more for the model to be confident).
- It finds the values of
mandbthat make the line pass as close as possible to all the data points at once.